Tech Talk: GOTO 2014 - Scaling Pinterest - Marty Weiner
From the YouTube video: GOTO 2014 • Scaling Pinterest • Marty Weiner
Slides are available on SlideShare
- Evolution:
- Started March 2010. Rackspace. 1 web enginer, 1 MySQL DB, 1 engineer + 2 founders
- Jan 2011: AWS, 1 nginx + 4 app servers, 1 mysql + 1 read slave, 1 task queue + 2 workers (emails, etc), 1 MongoDB (counters), 2 engineers + 2 founders
- Sept 2011: 2x growth every 45 days! More EC2, sharded DBs, 4 cassandra nodes, 15 membase nodes, 8 memcache, 10 redis, 3 task routers + 4 workers, 4 ElasticSearch, 3 MongoDB, 3 engineers, 8 total employees
- LESSONS:
- Everything will fail so keep it simple!
- If you’re the biggest user of a tech, the challenges are greatly amplified (bc you need to fix the tech)!
- April 2012: decided to rebuild everything and simplify the tech stack. DBs were a pain.
- Lots of EC2. 135 web engines, 75 API engines, 80 MySQL DBs + 1 slave, 110 redis, 60 memcache. 12 engineers, 10 non-eng. Were able to scale out now.
- Next problem: scaling people
- April 2013: split up into individual teams. Data pipeline, search, biz and platform, spam, growth, infra + ops.
- Then moved to San Francisco. Lots more people. More offices. Difficult to communicate.
- Technologies:
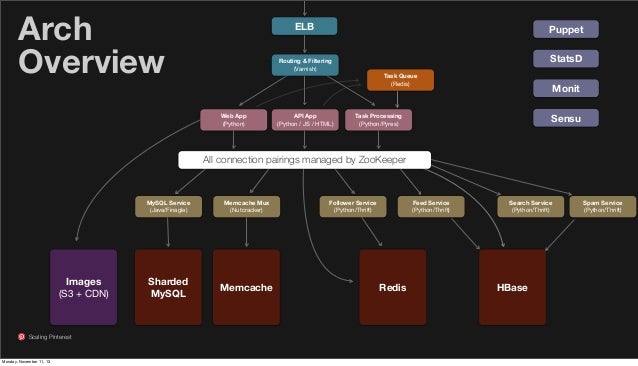
- ELB => software router => python web layer
- Every user-generated image lives on S3, fronted by CDN like Akamai
- Use Zookeeper to pair a web server (or whatever) with a backend service like search
- Each DB tech (mysql, memcache, redis, hbase) fronted by a service
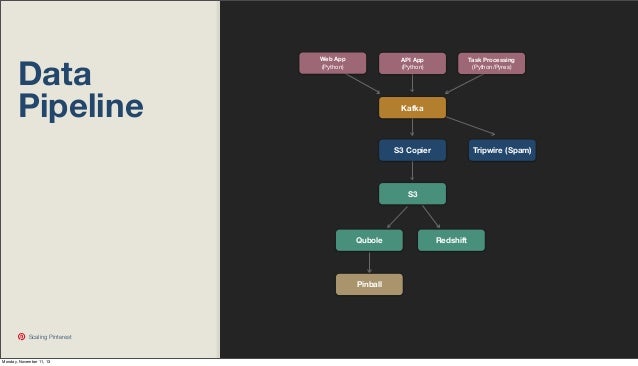
- Data Pipeline: everything goes into Kafka. Read from Kafka and process the data.
- Architecture
- Choosing your tech
- Does it meet your needs?
- How mature is it? (Maturity = blood and sweat / complexity)
- Is it commonly used? Can you hire people that know it?
- Is the community active?
- How robust is it to failure?
- How well does it scale? Will you be the biggest user?
- Does it have good debugging tools? Profiler? Backup software?
- Is the cost justified?
- Is it simple?
- Why AWS?
- Veriety of servers running linux
- Very good perifpherals: load balancing, DNS, map reduce, security, etc
- Reliable
- Active dev community,
- Not cheap, but new instances ready in seconds
- Route 53 for DNS, ELB as 1st-tier LB, EC2 Ubuntu Linux, S3 for images and logs
- Why Python?
- Mature, well known and liked, solid community, good libraries, rapid prototyping, open source.
- Some Java and Go. Faster, lower variance in response times. For anything high-cpu.
- Why MySQL and Memcached?
- Very mature, well known and liked, rarely fails, respone time increases linearly, good support, solid community, open source
- Why Redis?
- Well know, good community, good performance, variety of data structures, persistence, open source.
- Use for follower data, configurations, public feed pin ids, caching of mappings
- Why HBase?
- Small but growing community. Chosen bc it’s extremely fast non-volatile storage. Works well. Open source. Scalable.
- BUT: Hard to hire for.
- What happened to Cassandra, Mongo, ES, Membase?
- Didn’t pass the set of questions asked under ‘choosing your tech’
- Seems like they weren’t mature, were buggy, hard to operate, etc.
- What would I have done different if I could?
- Logging on day 1 (statsd, kafka, map reduce). Log every request, event, signup. Basic analytics. Recovery from corruption / failure. Kafka -> S3 -> MapReduce.
- Alerting on day 1
- Shard much earlier. Read slaves = time bomb.
- Don’t rely on NoSQL in the early days.
- Pyres for background tasks on day 1
- Hire technical ops eng earlier
- Chef / Puppet earlier
- Unit test earlier (Jenkins for builds)
- A/B testing earlier: decider on top of zookeeper; progressive rollout; kill switch
- Looking Forward
- More than 400 people
- Continually improve pinner experience, and collaboration
- Have fun, build a good culture, make sure employees are happy